
|
LongTail Driving Scenarios with Reasoning Traces: The KITScenes LongTail Dataset
Royden Wagner*, Ömer Şahin Taş*, Jaime Villa, Felix Hauser, Yinzhe Shen, Marlon Steiner, et. al. preprint, 2026 dataset / paper / benchmark A multimodal, multilingual dataset and benchmark to evaluate in-context learning and chain-of-thought reasoning in VLMs/VLAs. |
|
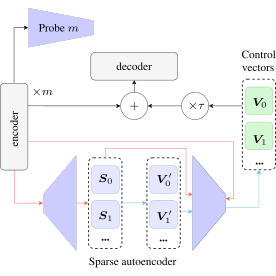
Words in Motion: Extracting Interpretable Control Vectors for Motion Transformers
Ömer Şahin Taş*, Royden Wagner* ICLR, 2025 project / arXiv / code / OpenReview / video / poster We find that neural collapse and concept alignment enable learning interpretable control vectors, which we refine with sparse autoencoders. |

|
Divide and Merge: Motion and Semantic Learning in End-to-End Autonomous Driving
Yinzhe Shen, Ömer Şahin Taş, Kaiwen Wang, Royden Wagner, Christoph Stiller TMLR, 2025 arXiv / code / OpenReview / video / poster An end-to-end autonomous driving approach that separates semantic and motion learning into parallel decoders to mitigate negative transfer. |
|
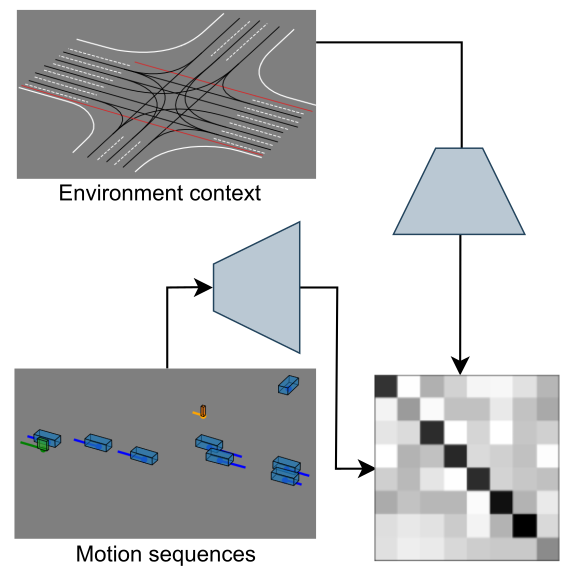
JointMotion: Joint Self-supervision for Joint Motion Prediction
Royden Wagner*, Ömer Şahin Taş*, Marvin Klemp, Carlos Fernandez Lopez CoRL, 2024 arXiv / code / OpenReview / video / poster JointMotion connects scene-level motion and environment embeddings via a non-contrastive alignment objective, then applies masked polyline modeling to unify global context and instance-level representation. |
|
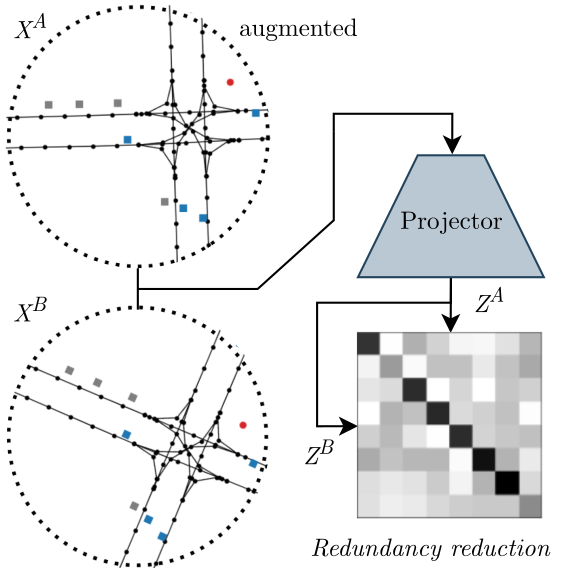
RedMotion: Motion Prediction via Redundancy Reduction
Royden Wagner, Ömer Şahin Taş, Marvin Klemp, Carlos Fernandez Lopez, Christoph Stiller TMLR, 2024 arXiv / code OpenReview RedMotion fuses local road features into a global embedding via an internal decoder, then applies self-supervised redundancy reduction across augmented views to unify local and global road representations. |